TrialMatchAI: Harnessing Large Language Models (LLMs) to Match Cancer Patients with Molecularly-driven Clinical Trials – Part of the European Open Science Cloud for Cancer Project
Introduction
In the fast-growing landscape of cancer treatment, the paradigm is shifting towards personalized medicine—a tailored approach that recognizes the unique genetic and clinical characteristics of cancer patients. At the core of this paradigm shift are precision clinical trials that drive advancements in personalized cancer therapeutics. By matching patients with treatments based on their unique genomic profiles, among other tumor characteristics, these trials can assess the efficacy and safety of therapies tailored to individual patients. Consequently, efficient trial-patient matchmaking ensures timely trial completion and maximizes the potential benefits of innovative treatments and interventions. Yet, aligning clinical trial eligibility criteria with individual patients profiles presents a notable challenge.
In many cases, multidisciplinary teams known as molecular tumor boards facilitate the process of matching cancer patients to molecularly driven trials. The molecular tumor board reviews individual patient cases in detail, considering various factors such as the patient's specific cancer type, stage of disease, genetic mutations or biomarkers, previous treatments, and overall health status. They might also incorporate the latest research findings and advances in molecular diagnostics to inform their decision-making process. However, the traditional method of manual matching patients to clinical trials is fraught with challenges, consuming valuable time and resources while potentially overlooking suitable candidates and trials.
Certain private firms have emerged as facilitators in this space, offering services that use closed-source automated systems to match patients with clinical trials. Companies such as MassiveBio and Tempus use advanced AI-driven technologies to improve the accessibility and personalization of cancer treatment through clinical trials. However, these companies typically charge for access to their databases and services, which can place a financial burden on patients and their families. Despite the potential for increased accessibility and efficiency provided by these firms, the cost barrier may limit the availability of these advanced tools to a wider audience, potentially exacerbating disparities in healthcare access.
Enter TrialMatchAI, our open-soruce solution to streamline patient-trial matchmaking developed by the Bordeaux Bioinformatics Center within the framework of the EOSC4Cancer initiative—a collaborative venture uniting researchers and institutions across Europe in the pursuit of accelerating data-driven cancer research. At its core, TrialMatchAI harnesses the power of cutting-edge Large Language Models (LLMs) and Vector Databases, sophisticated artificial intelligence systems capable of processing vast amounts of data with remarkable accuracy.
Code repo: https://github.com/cbib/TrialMatchAI
Why automate the matching of cancer patients to precision clinical trials?
Automating the process of matching cancer patients to clinical trials is a critical advancement with profound implications for personalized medicine for several compelling reasons :
-
Precision and Personalization: Cancer is a complex disease with myriad genetic, environmental, and personal variables influencing its progression and response to treatment. Clinical trials often target very specific patient profiles, particularly in the era of precision medicine where treatments are tailored to the genetic mutations of a cancer rather than its location in the body. Automating matchmaking allows for more precise alignment of a patient's unique clinical and genetic profile with the specific requirements of clinical trials, ensuring a highly personalized treatment approach. This can dramatically increase the likelihood of successful treatment outcomes.
-
Speed and Efficiency: The traditional process of finding appropriate clinical trials for cancer patients is time-consuming and labor-intensive, often involving manual searches through databases and clinical trial registries. This can lead to delays in starting potentially life-saving treatments. An automated tool can rapidly parse vast amounts of data from clinical trials and patient records, speeding up the matchmaking process significantly. By automating this task, patients can be matched with suitable trials much faster, which is crucial given the often time-sensitive nature of cancer treatments due to the rapid deterioration of patients' conditions.
-
Increased Trial Enrollment and Diversity: Many clinical trials struggle with recruitment and fail to enroll enough participants to meet their statistical requirements, sometimes leading to cancellations or inconclusive results. Automating the matchmaking process can increase the number of patients who are aware of and qualify for specific trials, thus boosting enrollment rates. Additionally, by expanding the search and matchmaking process beyond the most immediate and obvious candidates and patients who have better access to healthcare institutions, such systems can help increase the diversity of trial participants. This diversity is key to understanding how treatments work across different populations from different socioeconomic backgrounds, leading to more generalized and robust findings.
-
Reduced Burden on Healthcare Providers: Healthcare providers, including oncologists and clinical researchers, are often overburdened with the dual tasks of treating patients and keeping up-to-date with the latest research and clinical trials. An automated trial recommendation system can offload much of the burden of searching and evaluating trials, informing the decision making process of allocation patients and allowing healthcare providers to focus more on patient care and less on administrative tasks.
-
Data-driven Insights and Improvements: Utilizing automated technologies, such as AI, in the process of patient-trial matching can provide new insights into the data itself, such as identifying patterns or trends that may not be visible to human researchers. This can lead to continuous improvement in how trials are designed and executed, as well as how patients are treated.
Overall, automating the process of matching cancer patients to clinical trials can make significant strides in patient care and medical research, making it a key development in the fight against cancer. This approach not only streamlines the matchmaking process but also enhances the precision, speed, and effectiveness of clinical trial recruitment and personalization of cancer treatment. To achieve these goals, we leverage state-of-the-art AI technologies centered around Large Language Models (LLMs), which have revolutionized numerous industries with their capability to understand and generate human-like language.

What are LLMs? And how effective are they in facilitating the matching of patients with clinical trials?
A Large Language Model (LLM) is an advanced artificial intelligence system capable of recognizing, understanding, and generating text, among performing other complex tasks. These models are named for their extensive training on vast datasets, which enable them to process and understand language at a deep level. LLMs operate on a machine learning framework known as a transformer model, a specific type of neural network optimized for handling sequential data, which underpins their ability to interpret and produce human-like text. Large Language Models (LLMs) and their application in the healthcare sector, particularly in matching cancer patients to clinical trials, reflects a deep integration of AI capabilities with domain-specific requirements.
The Relevance of LLMs in Patient-Trial Matching
LLMs can interpret complex medical texts and patient records, sift through databases, recognize biomedical terms, and infer entailment or contradiction between texts, offering several significant benefits:
-
Enhanced Textual Analysis: Clinical trial documents and patient medical records are inherently complex, often involving convoluted medical jargon, inconsistent use of vocabulary, and dense informational content. LLMs excel in parsing such documents, extracting essential data points like eligibility criteria, genetic markers, clinical biomarkers, and patient demographics. This capability is important because it transcends mere syntactic recognition of keywords, allowing for a nuanced contextual understanding of medical texts, which is crucial for accurately matching patient profiles with trial requirements.
-
Semantic Precision: One of the standout features of LLMs is their ability to grasp the semantics of language—interpreting meaning beyond the superficial layer. In the context of clinical trials, this means LLMs can effectively match patients not just based on direct keyword matches but through understanding the underlying clinical contexts, potential treatment responses, and specific needs. Such semantic processing ensures a higher accuracy in trial-patient matching, potentially leading to better patient outcomes.
-
Scalability and Automation: The manual process of matching patients to trials is notoriously slow and labor-intensive, often limiting the scope and speed of patient recruitment. LLMs automate this process, significantly enhancing the efficiency and scale at which patient matching can be conducted. They can quickly analyze vast arrays of trial data and patient records to identify viable matches, thus accelerating the pace at which patients can access potentially life-saving treatments.
-
Medical Documentation and Data Analysis: LLMs can efficiently manage and analyze extensive medical documents, extracting pertinent information that can assist healthcare providers in making informed decisions. This capability is crucial for reviewing patient histories, medical research, or drug information quickly and accurately. Moreover, LLMs can help in building Vector Databases, which organize and index large datasets in a way that facilitates quick semantic retrieval and analysis. This is especially useful in healthcare, where the ability to semantically correlate different types of data—such as clinical outcomes, treatment protocols, and genomic information—can lead to more effective patient recruitment to trials.
-
Minimizing Human Error: While the human element is indispensable, particularly in ethical considerations and final decision-making, LLMs can minimize human errors in the preliminary stages of trial matching. They provide objective analyses and recommendations based on data, reducing the subjectivity and potential biases that might affect human reviewers.
In sum, LLMs have the potential to stand at the forefront of revolutionizing how clinical trials are conducted by making the patient-trial matching process more accurate, streamlined, and personalized. Their ability to process and analyze large volumes of complex medical texts quickly and accurately can significantly impact the field of oncology, enhancing the efficacy of clinical trials and the speed with which new cancer therapies are developed and delivered to patients. Integrating such advanced AI tools in healthcare promises not only technological advancement but also a substantive improvement in patient care and treatment outcomes. Next, we will see how TrialMatchAI's pipelines integrates LLMs at different stages of data processing leading up to a ranked list of trial recommendations.
TrialMatchAI Pipeline: And End-to-End approach
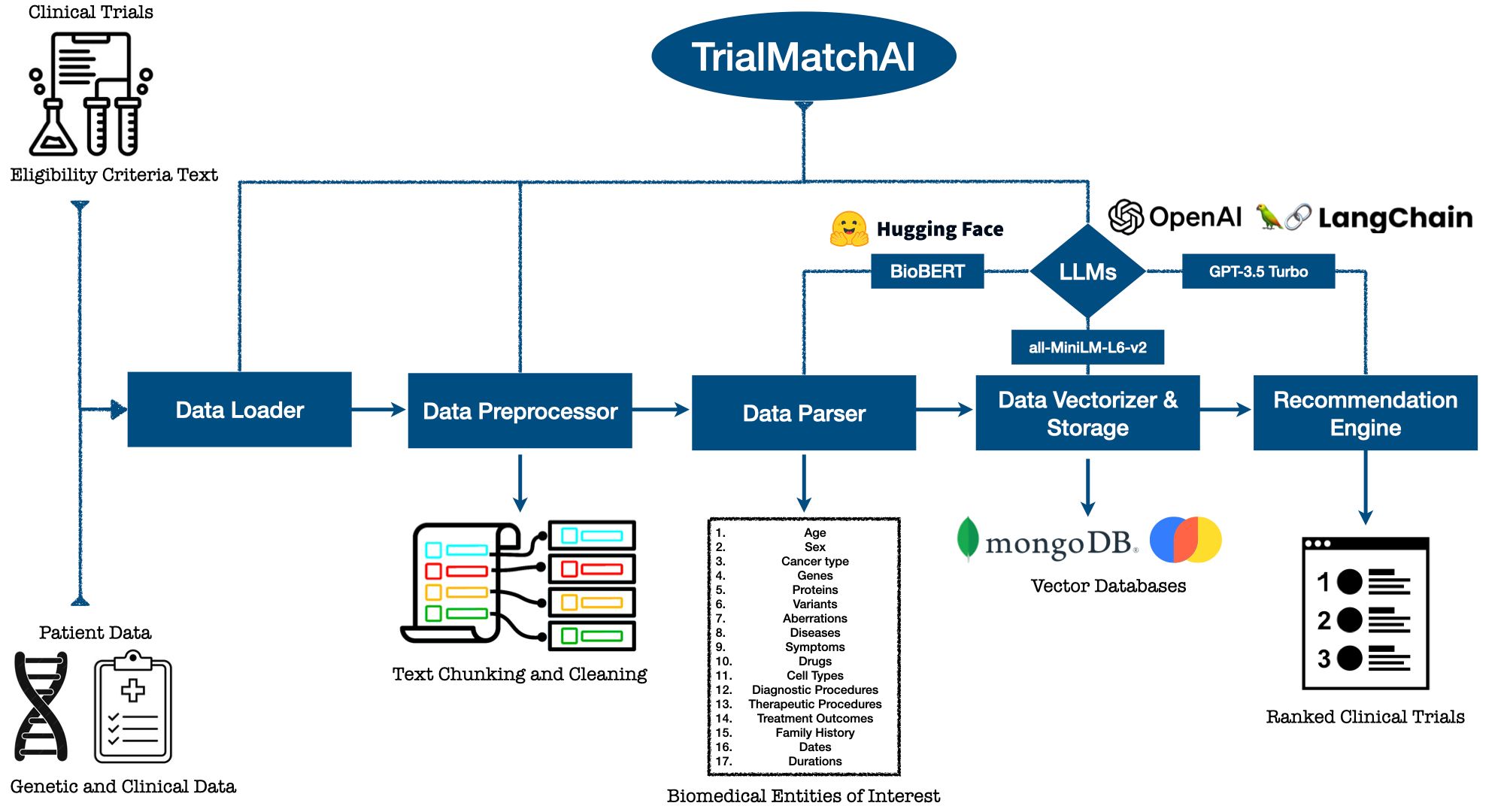
Figure 2: Schematic overview of the pipeline of TrialMatchAI. Link to the tool on Github.
TrialMatchAI comprises a data processing pipeline that can take in unstructured, semi-structured, or structured data — such as clinical notes, mutation reports, eligibility criteria text blocks — as input and returns a ranked list of clinical trials that are personalized for each patient.
At the start of the pipeline, a Data Loader module acts as a crucial gateway that facilitates the loading of diverse datasets from both public and secure sources. Equipped with a RESTful API, the DataLoader enables seamless connectivity with various clinical decision support systems. The RESTful API facilitates the dynamic exchange of data, ensuring that the information relayed from these support systems is timely and pertinent, thus setting the stage for a truly integrated approach to patient-trial matchmaking. This component curates data from two principal reservoirs: the richly detailed eligibility criteria from ongoing clinical trials and the comprehensive genetic and clinical profiles of patients.
Moving to the Data Preprocessor stage, the raw data is subjected to text chunking and cleaning. This process ensures data integrity and normalizes it, transforming it into a semi-structured format suitable for advanced downstream AI-based language processing tasks. The main motivation behind this preprocessing step is to accommodate the token limits of Large Language Models (LLMs), as these models handle shorter discrete texts more effectively than longer ones. The essence of this phase is its capability to condense extensive datasets into a more manageable and streamlined format, setting the stage for the parsing processes that follow. It is important to note that the pre-processing methods used to split clinical trials text blocks into discrete criteria were originally developed within the Clinical Research Metadata Repository (MDR) of the European Clinical Research Infrastructure Network (ECRIN) and generously shared with us to develop the Preprocessor of TrialMatchAI.
At the heart of the TrialMatchAI system is the Parser, empowered by domain-specific Bidirectional Encoder Representations from Transformers (BERT) models, such as BioBERT and PubMedBERT. We finetune these language models, tailor-made for the biomedical domain, on publically available and annotated biomedical named entity recognition (Bio-NER) texts that comprise published studies rich in biomedical terminology spanning multiple biomedical domains. The finetuning process enables these LLMs to extract an array of Biomedical Entities of Interest, such as patient demographics, mutational idiosyncrasies of cancer types, genes and proteins, diseases, medications, cell types, and diagnostic and therapeutic procedures. This step is where structured data are extracted from unstructured and semi-structured text to facilitate clinical trial eligibility criteria retrieval at later stages.
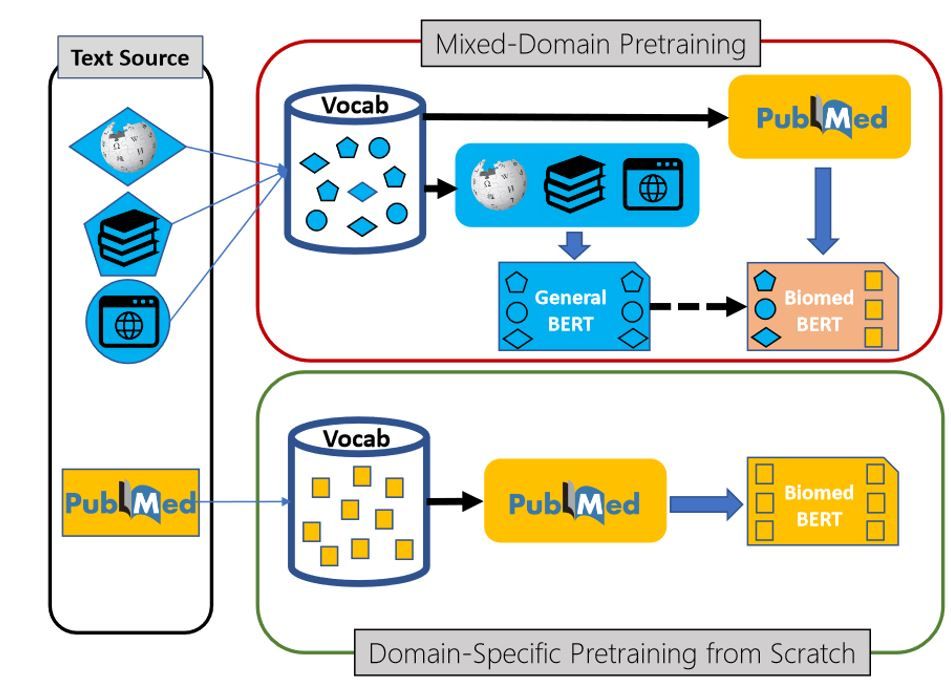
Figure 1: Overview of the Biomedical Natural Language Processing (NLP) Framework. More details can be found in this article.
As we transition to the Data Vectorization and Storage phase, both the structured and unstructured clinical trials data are transformed into higher-dimensional vector spaces using LLM embeddings from the sentence-transformers/all-MiniLM-L6-v2 model. This crucial step enables the system to capture the complexities of information embedded within the texts. This vectorization process not only retains the rich semantic relationships inherent in the texts but also prepares it for meaningful semantic search and retrieval of clinical trials enabled by vector databases, notably ChromaDB.
The Recommendation Engine represents the zenith of the TrialMatchAI framework, where a multi-stage filtering strategy allows for an efficient and accurate of retrieval clinical trials. In this phase, the LangChain library is used to design information retrievers. The first retriever takes in general information from the patient data, such as age, sex, cancer type, cancer stage, and preferred geographical locations to narrow down the scope of search to clinical trials that meet basic requirements. This initial filter significantly reduces the volume of potential condidates, making the search more manageable and targeted. The second stage comprises a hybrid search technique implemented on the level of individual eligibility criteria of the focused set of trials, which are stored as seperate documents in the database. Two types of retrieval strategies are implemented in this stage: comprehensive text-search and a vector similarity search. The first strategy harnesses the biomedical named entities extracted by the Parser and implements a BM25 algorithm to perform a keyword-based search, which identifies relevant documents (i.e., criteria data) by their content's proximity to the query terms (i.e., patient's data). This ensures that criteria with the most matching keywords are ranked higher, providing an initial layer of relevancy. The second strategy employs a vector similarity search, which utilizes the vectorized representations of the trial documents and patient data created during the Data Vectorization and Storage phase. This approach leverages cosine similarity measures to find criteria whose vector profiles are most similar in meaning to that of the query, capturing deeper semantic relationships that may not be immediately apparent through keyword matching alone. Finally, a cross-encoder neural re-reranker is used to re-rank the results of the hybrid search to refine the accuracy of the results. At the end of this stage an aggregaton of the criterion-level predictions is done to generate a trial-level score, taking into account the ratio of inclusion-to-exclusion criteria that match a patient's profile.
The culmination of this process is the generation of Ranked Clinical Trials—a meticulously curated list of clinical trials, each evaluated and ranked according to its relevance to the individual’s medical profile. Within this list, we utilize chat-based Large Language Models (LLMs) such as GPT-3.5-turbo and Zephyr to produce a summary for each selected trial. Employing a Retrieval-Augmented Generation (RAG) approach, these summaries articulate the trial's pertinence to the patient's condition, offering clear and transparent explanations to users about why a particular trial was recommended. This feature not only enhances understanding but also aids in making informed decisions about potential clinical trial participation.